Motivation
I think an aspect of adjudication that is often a bit overlooked is a probabilistic interpretation. Even though arguments are often “bought to some degree” or the judges are “convinced to some extend” we rarely talk about what that means. I have written a three-part mini-series about this topic on my blog where I try to be as detailed as possible. This post serves as a short motivation for and overview of the basic concepts. If you are unfamiliar with probability distributions you might want to check out the first paragraphs of Part I.
We don’t think about the world in a binary fashion. Our weather apps usually don’t say “It will rain” but “It will rain with a probability of 70 percent”. When we say something like “I am probably coming to the party” you express a probabilistic statement, i.e. you don’t say “I’m definitely coming” or “I’m definitely not coming” but rather “I am more likely to come than not”. Our decision making also works with probabilistic assessments. When the weather app says it will rain with 70 percent probability you might think: “well that is too much of a risk and I, therefore, do not go outside” or “I’m willing to take the risk”. These kinds of assessments not only happen on a small level in our daily lives but also in the decision making of governments and companies. If the experts say there is a 5 percent chance of a nuclear attack on the country the government will not reply “We will just round this 5 percent to 0 percent and do nothing”. If a company predicts that there is a 40 percent probability that a part of their supply chain will fail, they will likely think of alternative strategies even though it is less likely to happen than not. The reason for these decisions is because the actors in question used an expected value, i.e. the probability of an event multiplied with its harm/benefit. The expected damage of a nuclear scenario with 5 percent is still very large and a scenario where your supply chains brake with 40 percent might have catastrophic results for the company.
The basic message that I want to get out there is that the world is not binary, our decision making is not binary and therefore debating and adjudication should not be either. They should be probabilistic.
Beliefs are probability distributions
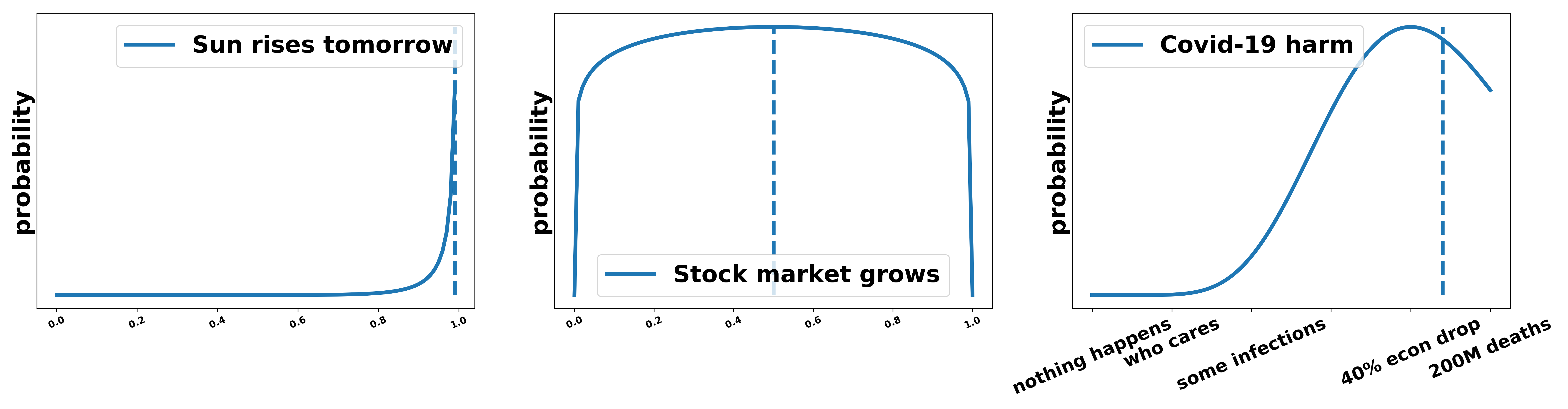
Having point estimates (i.e. percentages) instead of binary assessments of an argument is a good start. However, they do not tell the entire story. There can be a difference between two scenarios with the same assigned probabilities. We would, for example, say that around 50 percent of the outcomes of a repeated unbiased coin toss are tail and might also say that the probability of the stock market rising tomorrow is peaked around 0.5. The difference is in the uncertainty that we have about these numbers. While we are very confident that a number close to 50 percent is the correct one when it comes to coin tosses we were very uncertain about the actual state of the stock market. To include this estimate of uncertainty we can use probability distributions. The distribution over the belief that the sun rises tomorrow peaks at probability 1 and has very low uncertainty. The distribution of the global effects of CoviD-19 represents some kind of “large but with high uncertainty”. These distributions can be assigned to every claim or argument made in a debate and used to evaluate the strength of an argument. The reason why we prefer probability distributions over point estimates is two-fold: a) Distributions can encode uncertainty which can be relevant in debating. When two judges disagree it might just be because the argument carries large uncertainty and b) a distribution is a nice way to encode that the average informed voter/global citizen (AIV) is not just one person with clearly defined beliefs but rather the combination of many opinions which differ in varying degrees.
Arguments are probabilistic
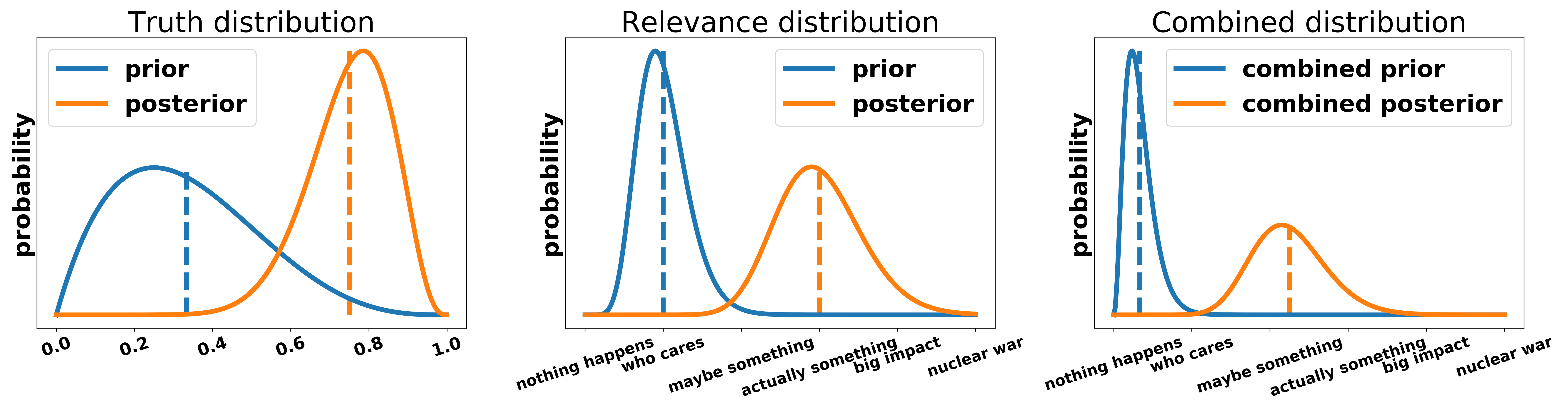
We can say that an argument is the combination of truth and a relevance distribution, which are answering the questions “How true is this argument?” and “How relevant is this argument?” respectively. The relevance distribution is NOT restricted to any kind of moral metric. Relevance can mean happiness/suffering, freedom, democracy, individual rights, etc. depending on the context and the arguments the teams decide to make. The strength of an argument can be evaluated as the combination of the truth and the relevance distribution.
About every belief we have a prior distribution, i.e. we already think an argument is plausible or implausible before it is made. However, this prior distribution can be shifted to a large extent via the arguments made in the debate. After all, we do not want our priors to influence the debate too much. Since debating is a sport in which we want to reward people for making convincing arguments rather than letting our priors determine the outcome of the debate we have to establish certain rules. The priors cannot be our personal priors but must roughly approximate the beliefs that the AIV holds. Additionally, these priors should be skeptical rather than naive, i.e. a team needs to provide reasons for an argument to be bought. Furthermore, a judge is able to be persuaded if an argument is made - the stronger the argument the larger the shift in the respective distribution.
Debating is more than evaluating a single argument
Other aspects of debating can easily be integrated into the framework:
- Rebuttal can be seen as a negative shift in the distribution of the argument being rebutted. The stronger the rebuttal the larger the shift. An argument can even be diminished to zero if the rebuttal is entirely refuting. Since rebuttal is constructive the rebutting team gets some credit proportional to the shift. This is discussed in Part II.
- An extension that is based on the same claim as the opening team’s arguments uses the posterior distribution of the opening team as prior. A closing team could, for example, provide better reasons than the opening team for why an argument is true and thereby extend the opening team. Whether the closing team beats the opening team can be determined by comparing the shift in the opening’s distribution with the shift from the opening’s distribution to the closings posterior distribution. This is also discussed in Part II.
- Weighing arguments on different moral metrics, e.g. happiness vs. freedom, can be integrated using an additional meta distribution. The more the teams persuade us that their metric is more important than that of the other team(s) the more they shift the meta distribution in their favor. Meta distributions also have priors. The priors reflect the moral beliefs of the AIV. In the debate “THW give more weight to young people’s votes” the AIV would presumably give higher weight to the metrics of democracy, fairness and happiness than religious freedom. This is discussed in Part III.
What’s the point?
Maybe this seemed entirely obvious to you but I was unable to find any resources on this part of debating and hope that at least some people might learn a thing or two. Besides that there are two aspects that I want to highlight.
- Outside of debates: Having a more or less formal framework of persuasion and adjudication is helpful because it brings people on the same page and forces them to think about inconsistencies in debating when an aspect is not easy to integrate. I, for example, had to realize that my understanding of “rebuttal is constructive” was rather vague and inconsistent. Explaining it through the probabilistic framework forced me to come up with a consistent solution.
- In a debate, especially when adjudicating: Obviously, I am not asking you to explicitly calculate the distributions over the teams’ arguments within a debate. This framework is more of a mental assistance. Adjudication is a complicated process. Within 15 minutes we have to coordinate different views on a debate that lasted for an hour and come to a decision. Fast and unified communication is key. When two adjudicators disagree about an argument, we can, for example, ask whether this disagreement is reasonably explained by the variance of the AIVs view on this argument. We can decide whether something was an extension by trying to identify to which degree the opening’s argument convinced us and then compare it to the degree that the closing’s argument furthered that belief.
Acknowledgements
I want to thank Julian, Samuel, Bea, Maria, Marion and Anton for the fruitful discussions, elaborate feedback and grammar-nazi skills (probably still contains some typos though).
One last note:
If you want to get informed about new posts you can subscribe to my mailing list or follow me on Twitter.
If you have any feedback regarding anything (i.e. layout or opinions) please tell me in a constructive manner via your preferred means of communication.