I want to grow the evals field and make it more accessible for people who want to start doing evals. My goal is that someone who is new to evals could either spend a day, a week or a month on the materials here and gain the most important evals skills and insights for that timeframe.
I think evals is extremely accessible as a field and very friendly to newcomers because the field is so empirical and hands-on. If you already have a lot of research and software engineering experience, you will be able to become good at evals very quickly. If you are a newcomer, evals allow you to get started with a minimal amount of background knowledge.
I intend to update this page from time to time. Feel free to reach out with resources that you think should be included.
A starter Guide to Evals
We have written a starter guide to evals as a general introduction to the field and suggestions on how to get started. If you prefer a presentation, you can watch this talk I gave for the Talos fellowship.
In general, because evals is such an empirical field, I would recommend to get your hands dirty as soon as possible by trying to measure something you’re curious about, as described at the bottom of the starter guide.
Inspect
Inspect is an open source evals library designed and maintained by UK AISI and spearheaded by JJ Allaire, who intends to develop and support the framework for many years. It supports a wide range of evals and is fairly easy to use. It is already used by a large number of people in the evals community and I think it will become the defacto standard tool for evals similar to how PyTorch is the defacto standard for neural networks.
At Apollo, we have also decided to switch to using inspect for our evals (see details here.
I think there is a lot of room for people to contribute to Inspect, e.g. there could be much more detailed tutorials. Contributing to Inspect might be a great way for people who enjoy the software engineering side of evals to test fit and gain career capital.
The ARENA evals materials
I worked with Chloe and James (they did most of the heavy lifting) to develop evals materials for ARENA. The materials are designed for a full week of training and aim to give you some basic skills for evals.
This was the first iteration, so there are still a lot of things we want to improve. We’re keen to get feedback from people who have either done ARENA or go through the materials in their free time.
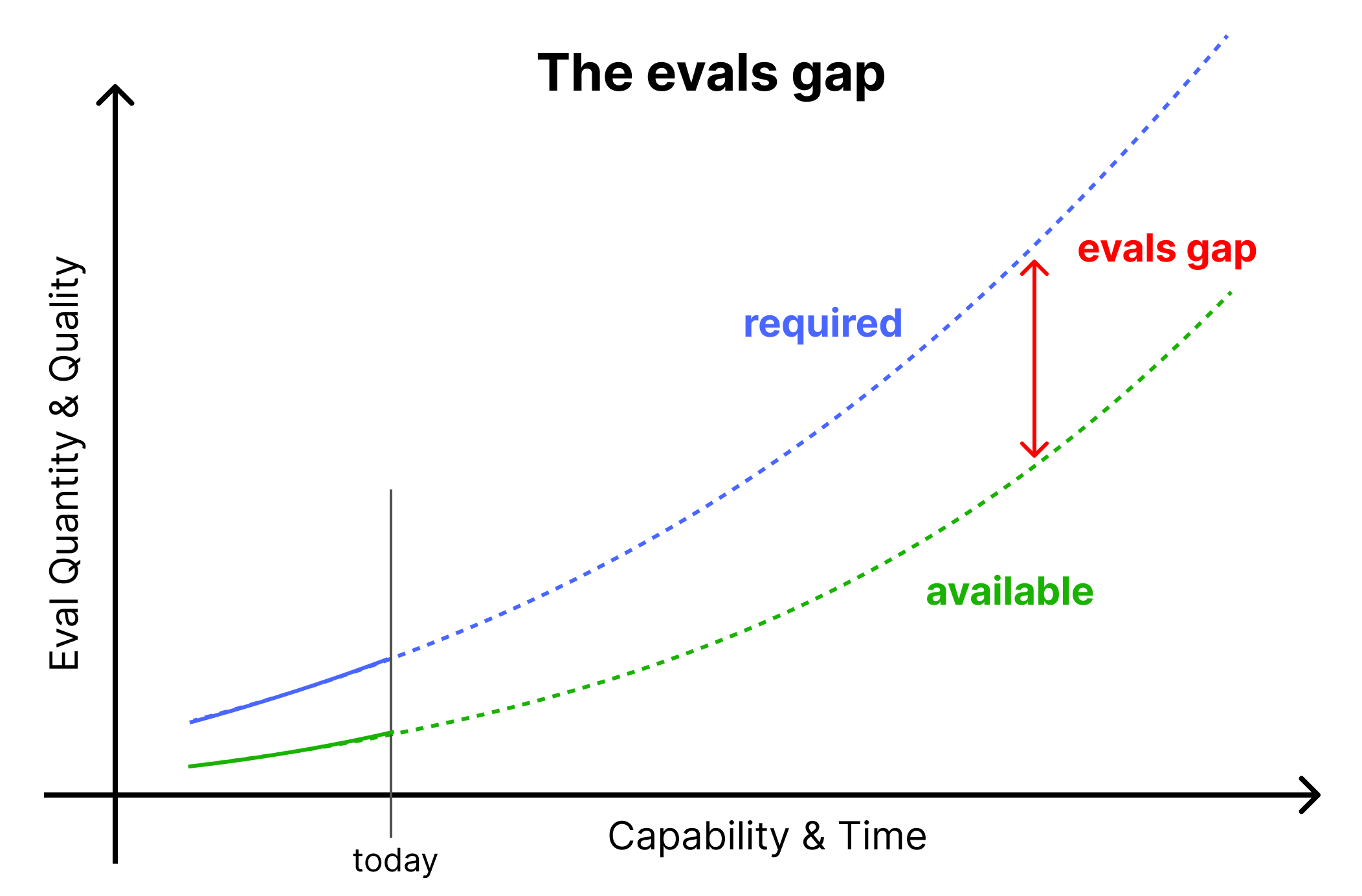
The evals gap
Evals underpin a lot of important decisions. I think most people have not yet internalized what kind of evals will be required to confidently support billion-dollar decisions. I think it is possible to build these evaluations but we have to try harder than we’re doing now. My evals field building efforts are partially motivated by the desire to close the evals gap (more details here).
An opinionated Evals Reading list
We have written a detailed opinionated evals reading list. We intend it to be useful both for people who just want to get a quick overview as well as people who want to understand the most important work in detail.
If you understand all the papers we listed as “core” well, I would claim that you know about 90% of the important ideas in evals (at least the ones that are publicly available; there is, of course, a lot of latent knowledge that hasn’t been written up yet).
Future plans and missing resources
Note: the following is largely “copy-paste what Neel Nanda did for the mechanistic interpretability community but for evals”. I think his work was great for the field, so why not give it a shot?
Broadly speaking, I want to make it easy and attractive for people to get involved with evals.
- Easy: Optimally, getting into evals should be as simple as logging into Netflix - one click, and you’re instantly part of a curated experience. There should be plenty of resources that feel enjoyable and neither too easy nor too hard for your level of experience.
- Attractive: When I first read through Neel Nanda’s A Mechanistic Interpretability Analysis of Grokking, I was hooked. I just needed to understand why the network is grokking. I couldn’t help myself, and spent a few days replicating the results and answering some additional questions about grokking. I didn’t do it because I had carefully reasoned that this was the most effective use of my time, I did it because I was intrigued. I think there are many similar situations for evals, e.g. when an LM agent unexpectedly solves a hard eval and you feel like you need to understand what else it is capable of, when it solves the eval in a clever way you hadn’t anticipated, or when you find a new powerful jailbreak. I think so far, the evals field has not done a good job conveying these aspects and that should be changed.
I think the following resources would be good:
- Open Problems in Evals list: A long list of open relevant problems & projects in evals. They should be a mix of ready-to-go well-scoped problems for newcomers as well as more complex, less well-scoped problems, e.g. for PhD students to work on. I have started such a list and multiple people have already confirmed that they will contribute to it. If you’re interested in contributing, please reach out.
- More Inspect Tutorials/Examples: Inspect already has a repository of examples, which is great. When I’m not familiar with a tool, I typically look for detailed examples and copy-paste or adapt someone else’s ideas. The more examples there are, the higher the chance it overlaps with anyone’s particular use case. The kind of examples I would like to see more of are:
- Examples with deep explanations, e.g. to get a much better sense of the considerations the evaluator is going through when designing the eval.
- Examples of complex agent setups, e.g. with multiple agents or new tools, to show how to build them.
- More detailed examples of the components around the evals, e.g. how to write detailed tests for the different parts of the eval. Another good post would be going through the paper “Adding Error Bars to Evals: A Statistical Approach to Language Model Evaluations”, showing results on real evals and making the code available.
- Evals playbook: A detailed guide on how to build evals with detailed examples for agentic and non-agentic evals. It should contain our current best guess and be updated over time. At some point, I started such a doc but I think almost all of the benefits come from the nitty gritty details and examples but I don’t have the time to write the details. If someone wants to work with me on this, I might be able to give high-level guidance.
- Salient demos: I think many people, including policymakers who follow the space of AI fairly closely, do not have a good understanding of a) what current LM agents are capable of and b) what the world will look like in a year or so when millions of LM agents are widely integrated in the economy. I think it would be great to have more demos that are very salient to people who are not working with frontier LLMs every day. These demos could cover safety-related aspects like scheming and CBRN misuse but I’m primarily looking for something that feels relevant to the life of normal people. I think CivAI has a few good demos in that vein but I’d be even more inclusive with topics. I don’t even necessarily want to build scary demos, I just want normal people to be less hit-by-a-truck when they learn about LM agent capabilities in the near future.
- More “day-to-day” evals process resources: A lot of evals expertise is latent knowledge that professional evaluators have accumulated over time. It would be great to get a better sense of how they work on a day-to-day basis. For example, I would welcome a video of someone building a semi-realistic eval for 60-120 minutes or a video of someone running an eval, e.g. to understand which evidence they are looking for, how they decide which scripts to read, how they track interesting findings, and more seemingly mundane aspects like that. This would be along the lines of Neel Nanda’s Real-Time Research Recording: Can a Transformer Re-Derive Positional Info? (though I would want it to be a little bit more prepared and fast-forwarding through the debugging parts xD).
- An evals slack: Maybe an evals slack would be nice. I’m currently not sure if the demand is large enough but if I get enough positive signal, I’d make one and put some effort into getting it off the ground, e.g. to make it useful for its members. UK AISI recently launched the Inspect Slack which I will closely follow to assess the demand and feasibility for a more general evals slack independent of a specific framework.
- Talk through the most important evals papers: Neel has made some videos of him going through interpretability papers he found interesting. I may do the same for evals papers (or maybe a bit closer to Yannic Kilcher’s style). I’d probably start with the top papers from our opinionated evals reading list but welcome other suggestions.
- Evals workshops and conferences: It would be nice to have specific workshops at big ML conferences. I don’t intend to spend any effort on this myself but if someone is keen to organize one, please do.
If you’re keen to be involved in any of the above, please reach out. In case you want to spend a few months on producing evals materials, I might be able to find funding for it (but no promises). If you’re a funder and want to support these kinds of efforts, please contact me. I would only serve as a regrantor and not take any cut myself.