Abstract:
In my first bachelor thesis I tested whether “inverting” the classification process by using gradient information of generative models is effective. In the thesis we used LSTMs as generative models. One of the open questions was whether using other generative networks might yield better results. Whether Generative Adversarial Networks (GANs) are effective is explored in this post.
Code for this project is openly available.
1. Introduction
An elaborate motivation of Inverse Classification (IC) can be found in the original post on my Bachelor’s thesis. The short summary is: It has been found that the human brain is, to a large extend, predictive, i.e. instead of using the stimuli from our environment to form a mental image of it the brain predicts a plausible image and merely adapts it using the stimuli. This kind of mechanism/framework could also be used for Machine Learning. Instead of using all the features of an image for its classification, we predict its most likely version and iteratively adapt it using the target. The reason we used Long Short-Term Memory cells (LSTMs) in the original thesis was that most of the data consisted of sequences and LSTMs are the natural choice for sequential data. However, we are usually not only interested in sequential data but also other data types such as images. A common choice to generate images are Generative Adversarial Networks (GANs) which work, as the name suggests, via an adversarial principle. This means that there are two models “competing” with each other. The generator tries to “fake” the most realistic version of an image and the discriminator has to decide whether it’s “real” or “fake”. The generator uses the information given by the discriminator to improve its “forgery”. The interplay between these two models yields more or less realistic images (see this intro). I want to point out that this was merely exploratory work, i.e. I just wanted to get a broad intuition whether GANs can be used for IC. It does not fulfill the requirements of rigorous research that a submission to a scientific journal or conference would involve.
2. Setup
In the original GAN setup the only input to the generator is noise. It would therefore be impossible to derive any class information from the gradients produced by the generator. Fortunately for us, there are conditional-GANs (see this intro) which close that gap. In conditional-GANs the generator and the discriminator receive the actual class inputs as one-hot vectors. The generator additionally receives some noise input to draw from a distribution of different types of a given class and thereby have some variability in the inputs.
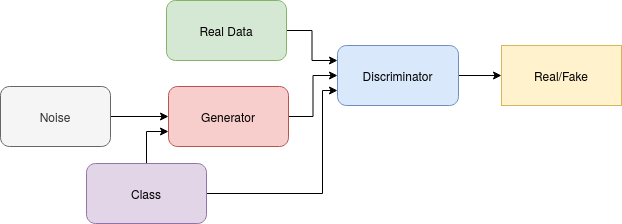
For reasons described in the Wasserstein GAN paper the training of the generator does not need to get better the longer you train. Therefore the model was saved every three iterations and the best model was chosen by visual inspection, i.e. I just checked whether the images generated when inputting all classes and some noise look reasonable. This is displayed in the following figure.

This is obviously not an optimal way of choosing the best model but it is sufficient to produce decent images.
3. Experiments and Results
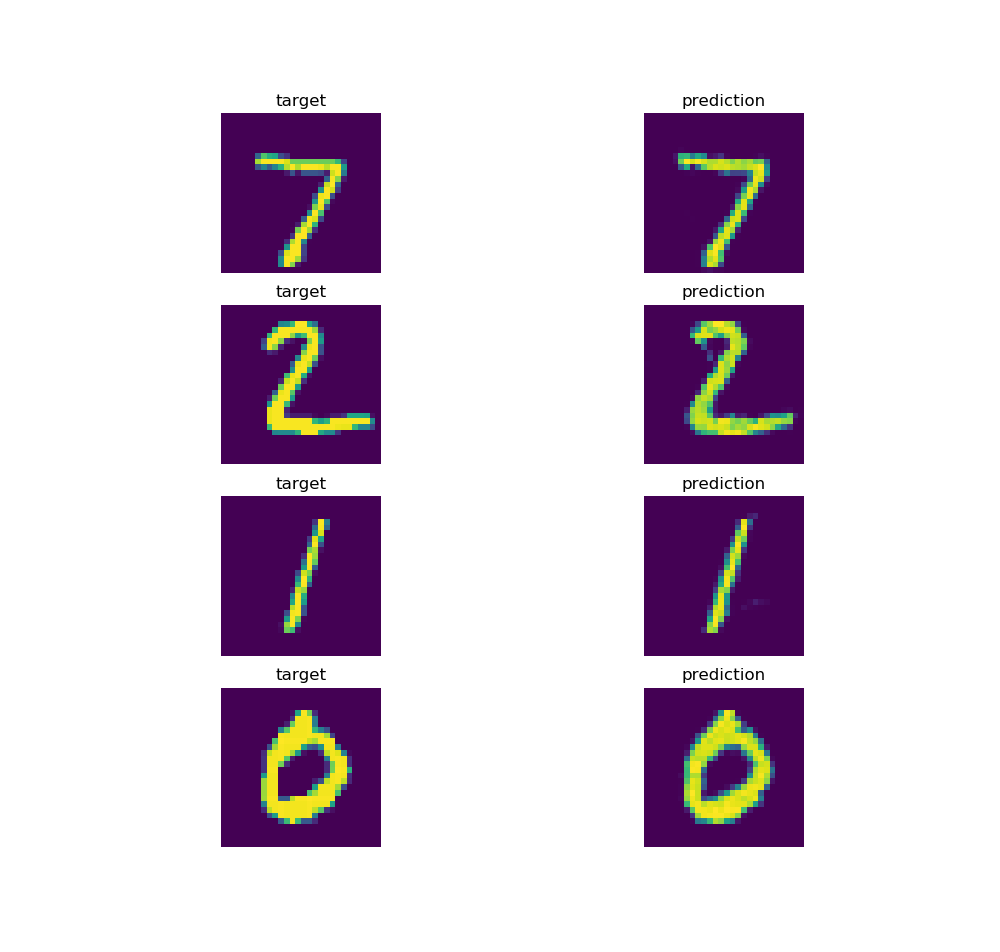
All experiments were conducted on MNIST. Even though MNIST is not terribly exciting as a dataset it can be seen as a test for feasibility, i.e. if this method does not even work on MNIST it is unlikely to work on any more complex datasets. Since the conditional-GANs generator has two inputs - classes and noise - I had to decide which of them I would update using the gradient information. At first I thought it would be reasonable to keep the noise input fixed and only update the class vector. However, I realized quickly that this produced pretty bad results since the noise information plays a large role in determining the shape, type, etc. of the final digit within the image. Therefore, I additionally optimized noise input. The optimization was done using an Adam optimizer. I also tested other optimizers such as SGD but Adam turned out to yield the best results. Unfortunately, if we optimize the noise as well it has more influence on the resulting image and thereby the class vector has less influence. The bottleneck for this technique to work is therefore to keep the influence of the noise on the image low while still producing sufficiently good images to increase the influence of the class vector. The following experiments, therefore, try different solutions for the just presented problem. All experiments have been repeated five times to reduce the randomness at least a bit. Before detailing the experiments I have to point out that the models were able to reconstruct the target images nearly perfectly as shown in the following figure.
1. Different sizes for the noise input
As a first solution, I tried different sizes for the noise input. The smaller the noise input vector the smaller its influence on the final image compared to the class input which always has size 10 (As there are 10 classes in MNIST). On the other hand, the noise input cannot be too small because it would reduce the expressiveness of the generator. To find out where the optimum lies I tested sizes that are presented in table 1 with their respective results:

We find that the size of the noise input does have some effect on the overall accuracy. A size of 25 seems to be optimal - probably because it is sufficiently expressive but not too influential compared to the class vector. However, an overall accuracy of 71 percent is rather bad, considering that very easy methods like nearest neighbor algorithms can already achieve accuracies far beyond 90 percent on MNIST.
2. Different gradient update rates
To strengthen the influence of the class inputs on the Inverse Classification process I introduced different update rates for the gradients. This means that the gradient for the noise input is only updated with a factor, e.g. 0.5. I hoped that this would lead to the process giving more weight to the class input and thereby increase the accuracy.

The results show that this method does increase the accuracy slightly for a value of 0.5. For sake of completeness I also confirmed that increasing the factor to 2 yields the expected result of a lower accuracy - presumably because the influence of the noise is stronger.
3. Late noise gradient update
To decrease the influence of the noise input on the Inverse Classification process we can also not update the noise for the first couple of iterations and only start the updates afterward. To test this hypothesis, I conducted experiments for different values of iterations.

Similarly to the previous experiment, we find that slight increases can be gained by starting to update the noise input only after 10 iterations.
4. Conclusions
I think there are three basic conclusions that can be drawn from these experiments:
- The technique of Inverse Classification has some potential. As shown in the image in experiments the reconstructions of the image are nearly perfect. Therefore the gradient updates yield meaningful results.
- It does not work with this setup. With some of the experiments we are able to increase the accuracy for a couple of percents but it is still around 20 percent away from simple other techniques. The reason for this is likely that the noise plays a non-negligible role in the construction of an image. A way to fix this would be to find a setting in which the only input for the generator is the class vector and nothing else. If you have any suggestions I would be interested.
- Images might not be the best application for IC. Inverse Classification needs to have a distance function to compare the target and the current reconstruction. For simple images like MNIST a simple mean-squared-error might be sufficient but this does not work for CIFAR or ImageNet anymore. Maybe slight increases can be gained by using slightly more appropriate distances but to my knowledge there currently is no very robust distance measure for images.
One last note
If you want to get informed about new posts you can subscribe to my mailing list or follow me on Twitter.
If you have any feedback regarding anything (i.e. layout, code, or opinions) please tell me in a constructive manner via your preferred means of communication.