What is this post about?
As an Effective Altruist with a quantitative mindset, I ask myself many different questions about the suffering in the world. A very fundamental question that I have asked myself for a long time is “How much suffering exists in total?”. I could finally bring myself to crunch the numbers and produce a rough estimate. Especially when it comes to cause prioritization it would be important to have some approximations of net human suffering, for example, to compare the suffering of animals to that of humans. In this post, I will try to give a rough estimate of the absolute and relative amounts of suffering of humans that exists now and has existed in the last 30 years. In future articles, I hope to do the same for animals (see Part II).
The hard work has not been done by me. The data come from our world in data and prb.org who themselves have aggregated many many sources - I merely crunched some numbers, plotted and interpreted them.
Update 07.07.20
Following the article, I had some interesting discussions that lead me to write this short update.
- DALYs clearly don’t capture all of suffering. My current belief is that suffering has a physical and a mental component and that DALYs are an approximation for the physical component. A better metric would be Well-being adjusted life years (WALYs) but there is no data available so far. I don’t the partition of influence for the physical and mental component or whether this distinction is even possible - in the end pain is always in your mind. However, for this post, I will assume that such a distinction is at least approximately possible but I will not commit to a specific ratio since it is too dependent on the situation of each individual. Even though this article is mostly concerned with the physical component I still think it yields insight into the human trajectory. Note, however, that while reading the post you should keep in mind that whenever I write suffering I mean only physical suffering.
- Some people have questioned whether it is even possible at all to quantify suffering since it is a merely subjective experience. While I can’t give proof I currently believe you can and should attempt to quantify it. First, I think we can agree that for a given individual we can at least give a ranking of the suffering induced by different situations. If I cut myself in the finger I probably have less pain than if I shoot myself in the stomach. I would think that we can go from these rankings to more fine-grained numerical scales. A bee sting could be twice as bad as stepping on a LEGO block for a specific individual. If we measured data for many different individuals we could assign means and variances for all different kinds of pain. The second question is whether suffering can be compared between different subjects. It might be possible that the “objective pain” induced by a bee sting is a million times higher for you than for me but I think that is not how we operate in real life. If you are on a camping trip with two friends and you only have one aspirin left, friend 1 reports mild headaches and friend 2 reports strong headaches, you would probably give the aspirin to friend 2. If we assumed that mental states were categorically incomparable we would not prioritize one over the other but would have to toss a mental coin to decide - after all friend 1 could be a utility monster and his pain is multiple orders of magnitudes larger than that of friend 2. In reality, we do prioritize though - we also do that in the context of pain medication in hospitals and during times of war. Even though it becomes more complicated we can still assign rankings and numbers to these kinds of weighings. They will clearly be imperfect and have high upper and lower bounds but it seems possible in principle.
Burden of disease and DALYs
Burden of disease quantifies the impact of a health problem by financial cost, mortality, morbidity or other indicators. It is often quantified in terms of quality-adjusted life years (QALYs) or disability-adjusted life years (DALYs). Both metrics approximate the number of years lost due to disability (YLDs), sometimes also known as years lost due to disease or years lived with disability/disease.
DALYs are calculated using two components - years of potential life lost (YLL), i.e. how early did you die compared to your life expectancy, and years of life lost due to disability (YLD), i.e. the number of years of good health that were taken away from you by the disease. The formula is a simple non-weighted sum: DALY = YLL + YLD. The following figure from Wikipedia should make the concept more clear.

In my approximations, I use DALYs and not QALYs because the data was only available for DALYs and I think the metric is more common when it comes to quantifying public health than QALYs because QALYs operate on a more individual level. DALYs are probably far from a perfect measure for suffering as I will discuss in the last section but it’s the only one we have wide-spread data for.
The Wikipedia articles for QALYs, DALYs and disease burden are really informative and easy to understand. I would recommend to check them out.
Shut up and calculate
The ourworldindata data on disease burden provides ‘DALYs per 100K people’ for every year since 1990 and nearly every country in the world. We will therefore first have a look at the relative measures and then multiply these with the respective population of the country to account for the global population growth since 1990. There are lots of other interesting facts about disease burden in DALYs that I will not discuss in this post such as an analysis of disease burden by age or cause over time. I would highly recommend to check out ourworldindata.org and have a look at their charts - they are amazing and every data nerd’s wet dream.
Relative suffering - DALYs per 100K people
Let’s first look at the seven countries that have the lowest average DALYs over the years from 1990 to 2017.
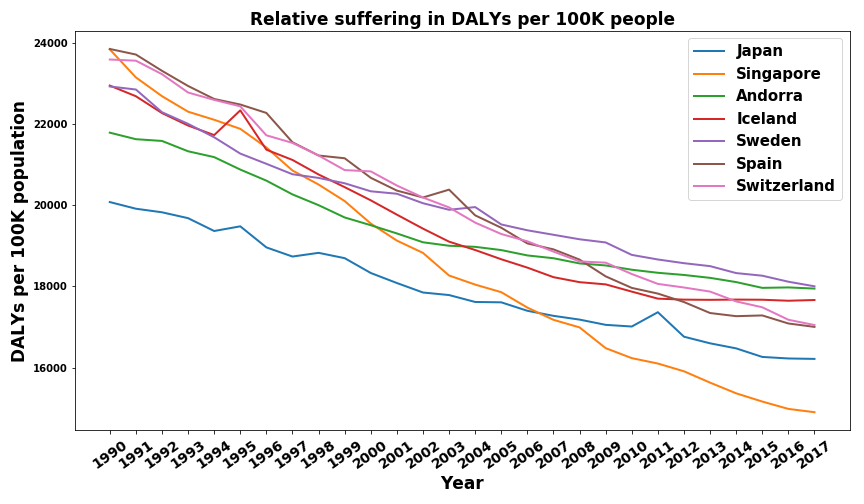
I found the results a bit surprising. Iceland, Sweden, and Switzerland were the ones I expected most. I would have also expected Norway, New Zealand, and Canada to be there (they are in the top 20). I was a bit surprised by Japan’s and Singapore’s very good results. Further analysis shows that other East Asian countries such as South Korea and Taiwan also perform very well. My hypothesis is that these countries have generally well run health care systems, healthier diets, and a more caring mentality towards their elderly than western countries do and therefore have smaller disease burdens. The countries that surprised me the most were Spain and Andorra. I would have, for example, predicted Germany to be above Spain. Further analysis shows that a lot of the Mediterranean Countries (Italy, Greece, Cyprus, Malta) have very low disease burdens. My current hypothesis is that the Mediterranean diet is very healthy and is less prone to lead to cardiovascular diseases who are by far the largest contributor to disease burden in developed countries. I want to emphasize that I am no health expert and my explanations for East Asia and the Mediterranean countries are of a very speculative nature.
To compare this, let’s have a look at the countries with the highest average relative suffering over the years from 1990 to 2007. Once with Rwanda
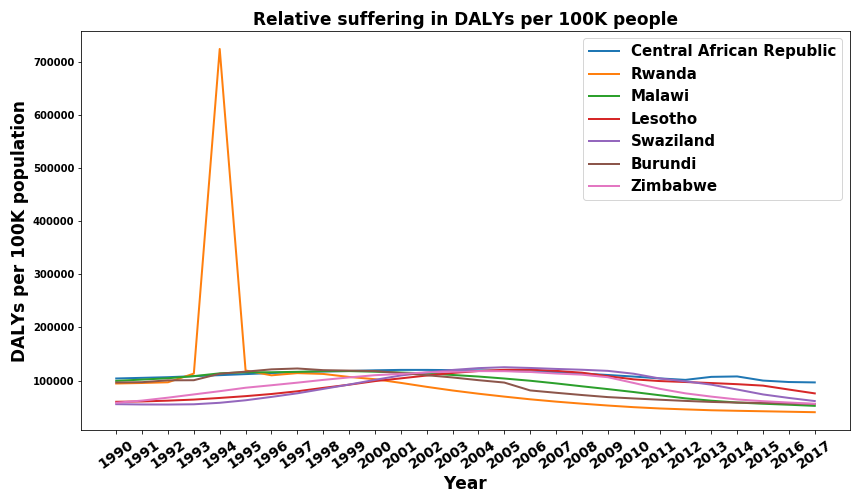
and once without Rwanda.
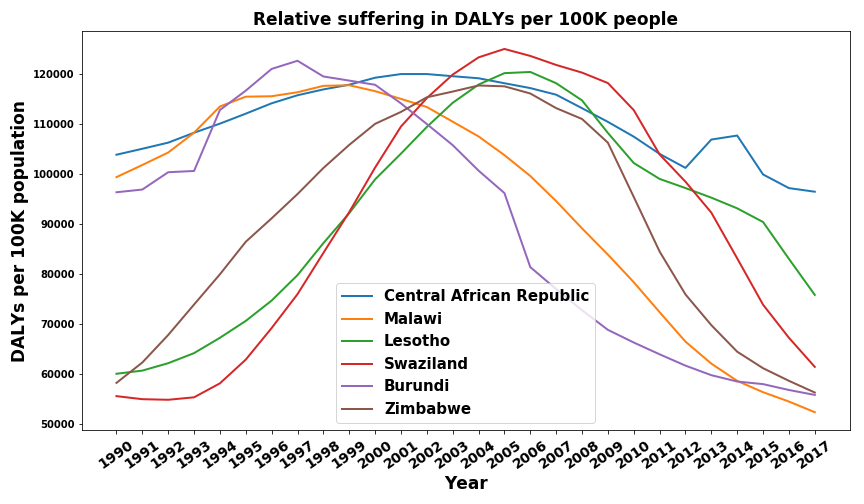
Let’s first discuss the elephant in the room - Rwanda 1994. I knew the genocide was really really bad, I had read the Wikipedia article, seen documentaries, and knew of the killings, the rapes, and the torture. But holy shit did I underestimate the suffering that must have been inflicted in the 1994 Rwandan genocide. 724,000 DALYs per 100,000 people means that in just one year, on average, every single person in Rwanda was robbed of more than 7 years of a good life. That’s just crazy.
Looking at the other trends we find that all seven countries are located in Sub-Saharan Africa and that their trajectory is not linear. In fact, all of them seem to have a period of increasing relative disease burden before it decreases again. In all cases, this is a longer, multi-year span and can therefore not really be attributed to specific coups, civil wars, or political events. Even after informing myself on all countries that display this trend I still can’t find a coherent, unifying hypothesis for this behavior. I would be interested in more expert opinions (please contact me if you have one).
Lastly, I want to compare the scope between the countries with the highest to the ones with the lowest disease burden. The disease burden per 100K people for the Central African Republic was around 100,000 while for Singapore it was around 16,000. If we use disease burden as a proxy for suffering, the amount of suffering for an average Singaporean would be around 6 times lower than that of the average citizen of the African Central Republic. This seems like some pretty clear evidence in favor of the lottery of birth argument to me - if you disagree I’d be happy to hear your explanation.
Not only the high and low ends of the spectrum are interesting and I, therefore, want to have a last look at a selected group of countries. These are some of the world’s largest and most influential ones.
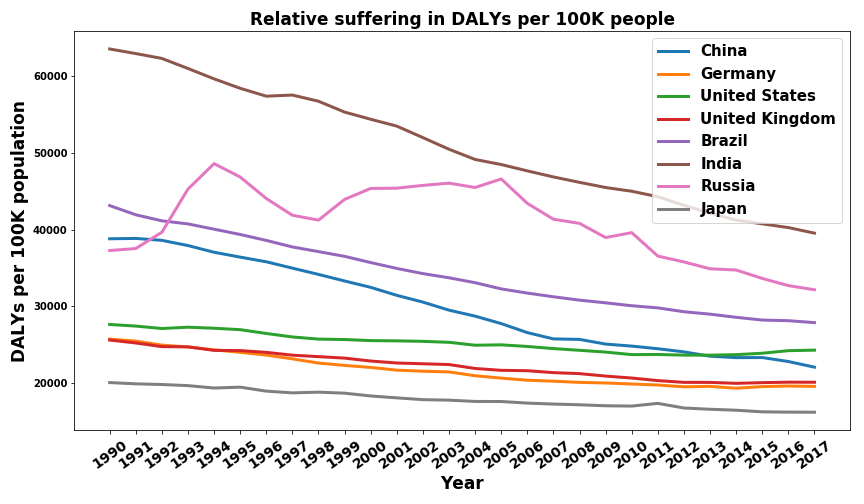
We can see that the general trend is a nearly linear decrease in DALYs per 100K per year. This is a good sign, especially since the two most populated countries in the world, China and India, have a steep downward trend. Russia, on the other hand, does not show the same decrease. After the break down of the UdSSR, Russia seemed to have a significant increase in average suffering. Another small but potentially significant detail is the trajectory of the USA. It decreases lower than other developed nations and also shows a slight upward trend in the last couple of years. I guess the effects of systematic wealth inequality, a broken democracy, and a terrible health care system slowly had to catch up at some point.
Absolute suffering - DALYs aggregate
The relative suffering is interesting but we can look at suffering from a different angle as well. Instead of only looking at the disease burden per 100K we can also account for the increase in population over the last thirty years. The decrease in average relative suffering in the world could, for example, be negated by the increase in the number of people and therefore the aggregate disease burden could have stayed constant.
The sum of DALYs per year for selected countries can be found in the following figure.
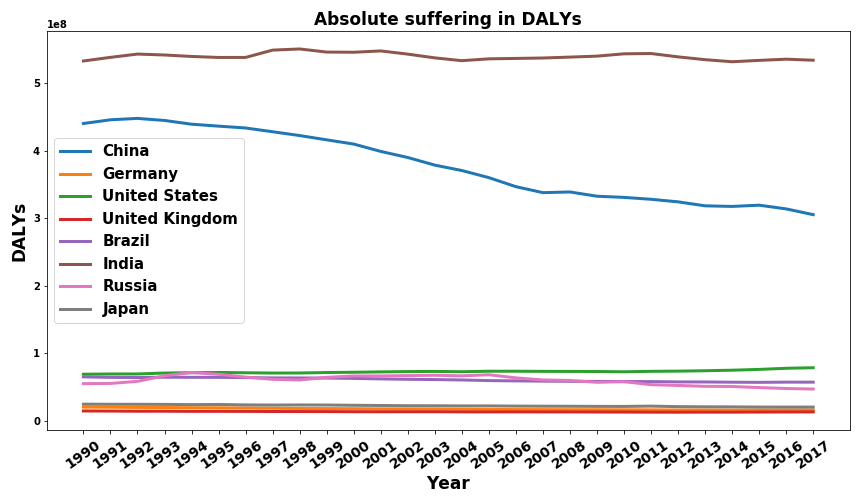
This seems to indicate that China was able to improve the quality of life faster than its population growth since the aggregate is decreasing. India’s population grew as fast as the quality of life per individual improved.
Removing China and India from the graph to get a better picture of the other countries we get:
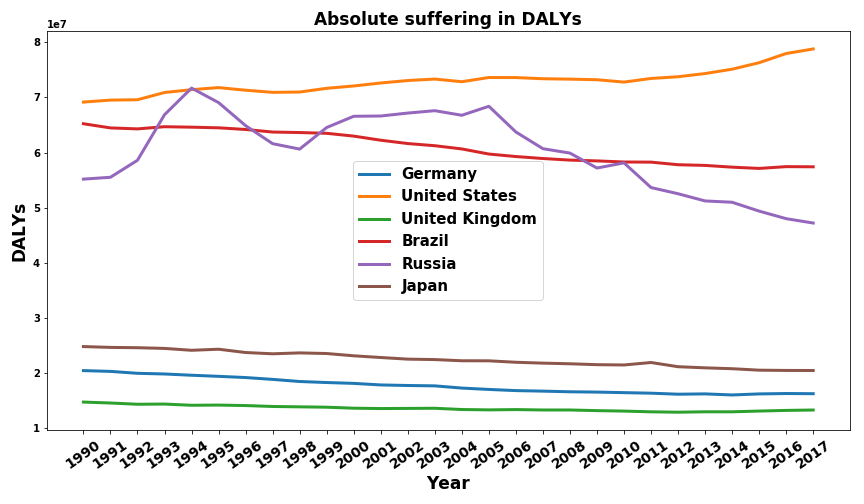
We see that Germany, Japan, the UK, and Brazil follow a somewhat similar trend. Their overall disease burden decreases slightly. As we have seen before their relative disease burden decreases more drastically, implying that they are able to keep up with their low to medium population growth. The USA, in contrast, is one of the few developed nations, that has an increased absolute disease burden over this time period. Even in the times in which their relative disease burden decreased the population grew faster than the living standards improved. Russia has had nearly no change in the size of its population and therefore the absolute disease burden shows the same trajectory as its relative counterpart.
Lastly, I want to present a holistic comparison of the relative and absolute global disease burden. The relative disease burden is weighed by the countries population.
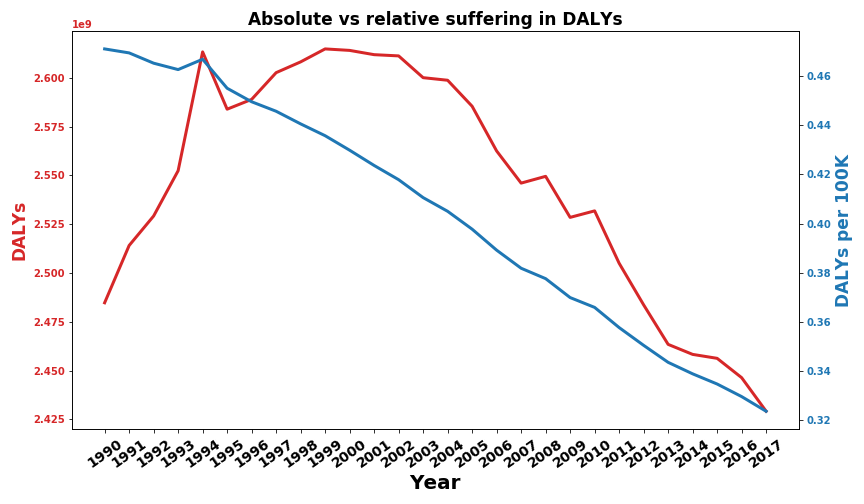
The positive news is that the relative disease burden seems to decline steadily. The alleviation of poverty and the eradication of diseases seem to work well on average. The absolute disease burden has increased from 1990 to 2000 but has since then decreased below the point of 1990. This seems to indicate that the progress humanity has made on improving living standards is faster than the growth rate of the global human population. One event that stands out in both metrics is the Rwandan genocide from 1994 which, again, I really did not expect. A country that had around 7.2 Mio inhabitants before the genocide and 5.8 Mio after it has had a visible impact on the global disease burden of 5.7 Billion people.
Nerd section - Data preparation
Skip this section if you don’t care about the data preparation process.
I used three datasets in total. The burden of disease dataset (see here) to get the DALYs per 100k people numbers, the population by country dataset from our world in data (which includes data from 1500-2000 in gaps of at least ten years) and a population by country snapshot by prb.org for the year 2019. Since the burden of disease dataset only includes the years from 1990 to 2017 I removed all data prior to 1990 from the population by country dataset which then included data points for 1990 and 2000. All three datasets included some countries that are not in the other two so I removed all countries that are not in the burden of disease dataset and used estimates to fill gaps in the 1990 and 2000 data points for missing countries. This means that there are some countries for which I don’t have any data points but most of them are very small like Saint Kitts and Nevis and Micronesia and therefore should not be a large source of error. To get the population estimates for the years from 1991 to 1999 and 2001 to 2018 I used a linear interpolation. I then cut the years 2018 and 2019 from the population data and merged it with the burden of disease dataset. This linear interpolation is definitely inaccurate but it is a sufficient proxy to start with. I am aware that population growth is usually approximated with a sigmoid but if you only have three datapoints the result is probably as bad as a linear estimate.
Conclusions
Some conclusions I reached during the entire process of researching and writing this post.
- The world seems to get better: especially the relative burden of disease steadily decreased from 0.46 DALYs per Person to 0.32 as a global average. This is a really significant improvement. It means that on a global average we only have 2/3 of the disease burden of our parents’ generation.
- New unanswered questions: Some of the trends I don’t understand. Why does the absolute disease burden increase until around 2000 and then turn back down? What explains the trend in relative suffering for Sub-Saharan countries discussed in the “relative suffering” section? Why is the burden for east Asian countries and Mediterranean countries so low compared to their wealth? If you have some plausible hypotheses please share them with me.
- Rwanda 1994: I knew the suffering was immense and I still underestimated it by a factor of 2 or 3. No other event of the last 30 years is that visible in the DALYs measurement. Not the financial crisis of 2008, not the earthquakes in Haiti or Nepal or the massive tsunami in 2004 that flooded large parts of Indonesia and Sri Lanka, and not even the wars and conflicts in the middle east. These catastrophes meant that entire countries had to be rebuilt and yet the estimate of 181K DALYs per 100K people for Haiti in 2010 comes second by a large margin to the incomprehensible 724K DALYs per 100K people for Rwanda in 1994. Just WTF.
Why should we care?
While this was an interesting and partly disturbing mental exercise for me, I think that it also yields some benefits.
- We can compare the absolute and relative human suffering in the world over time. This means we can test whether the world is becoming a better place on average and at which rate, as I have just done. It should be seen as foundational work that can be used as a baseline measure for humanity’s progress.
- We can compare the absolute and relative human suffering to the suffering of other species. I’d find it interesting to see how much suffering is inflicted on animals due to factory farming or wild animal suffering. I will, therefore, extend this question to animals in a future blog post (see Part II).
What could be improved in my modeling
My approximations make a couple of crucial assumptions, all of which could be improved with more effort and research. Sources of error include
- DALYs are not an accurate measure of human suffering. This is especially because DALYs partly measure years of life lost which, strictly speaking, should not contribute to suffering since the person is dead. However, you could also argue that some of the suffering comes from losses in human capital due to lost workers and family members. Even though it’s an imperfect approximation, DALYs are the most accurate measure we currently have data of. But there are good ideas and approaches on better approximations, e.g. this blog post by Simon Knutsson or this article by the happier lives institute.
- Not all suffering is already captured by current measurements. This is a big problem, especially for mental health issues in the developing world. While more developed nations slowly realized that mental health is important and that depression is something that often requires therapy or medication, large parts of the developing world still lag behind. Depression is often frowned upon and seen as a sign of weakness and the mentally ill are often ostracized instead of helped. This means that the data we have about mental health is probably very inaccurate but I would estimate that they play a large role in the true net suffering of humanity. Overall this leads me to believe that I drastically underestimate the actual amount of suffering.
- “Small and daily suffering” such as having a bad day or lovesickness is not part of the DALY estimation and therefore not part of my model. I am not sure to which extent they would play a role but it is surely non-negligible if aggregated over the entire world.
- For some reason, I could not find a publically available dataset for the population sizes per country that includes all years from 1990 to 2017. I, therefore, had to merge and linearly interpolate datasets from 1990, 2000, and 2019. This is clearly suboptimal and better modeling and data would give more accurate estimates.
I could not answer a lot of interesting questions that could be asked about global suffering such as “which causes have become more prominent over time?” or “Can we extrapolate from the last 30 years to the future in a meaningful way?”. While I intend to model some of these questions in future blog posts you might be interested in trying to improve the model by using better data or incorporating more features or just ask other interesting questions. If you want to build on my work don’t hesitate to pull the respective github repo and contact me to coordinate the research.
One last note
If you want to get informed about new posts you can subscribe to my mailing list or follow me on Twitter.
If you have any feedback regarding anything (e.g. layout, code or opinions) please tell me in a constructive manner via your preferred means of communication.